Text classification to detect toxic comments using Azure ML Services for Kaggle Jigsaw competition
Pipeline author: Andrey Vykhodtsev
Attribution
My work here is focused on tooling, monitoring, execution, clean pipeline and integration with Azure services. Other code was adopted from many public kernels and github repositories that can be found here and here. I tried to keep the references to original kernels or githubs in the code comments, when appropritate. I apologize if I missed some references or quotes, and if so, please let me know.
About this solution
This is the pipeline I developed during the Kaggle Jigsaw Toxic comment classification challenge. In this competition, I focused more on tools rather than on winning or developing novel models.
The goal of developing and publishing this is to share reusable code that will help other people run Kaggle competitions on Azure ML Services.
This is the list of features:
- Everything is a hyperparameter approach. Config files control everything from model parameters to feature generation and cv.
- Run experiments locally or remotely using Azure ML Workbench
- Run experiments on GPU-based Azure DSVM machines
- Easily start and stop VMs
- Add and remove VMs to and from the VM fleet
- Zero manual data download for new VMs - files are downloaded from Azure Storage on demand by code.
- Caching feature transformations in Azure Storage
- Shutting down the VMs at the end of experiment
- Time and memory usage logging
- Keras/Tensorboard integration
- Usage of Sacred library and logging experiment reporducibility data to CosmosDB
- Integration with Telegram Bot and Telegram notifications
- Examples of running LightGBM, sklearn models, Keras/Tensorflow
Presentations and blog posts
This solution is accompanying a few presentations that I gave on PyData meetup in Ljubljana and AI meetup in Zagreb. Links to the slides:
I am also writing a blog post which is going to published here.
Technical overview of the solution
This sample solution allows you to run text classification experiments via command line or via Azure ML Workbench. To see, how to run, configure and monitor experiments, refer to the Standard Operating Procedures section. If you wish to extend or modify the code, please refer to [Modifying the solution]
Pipeline
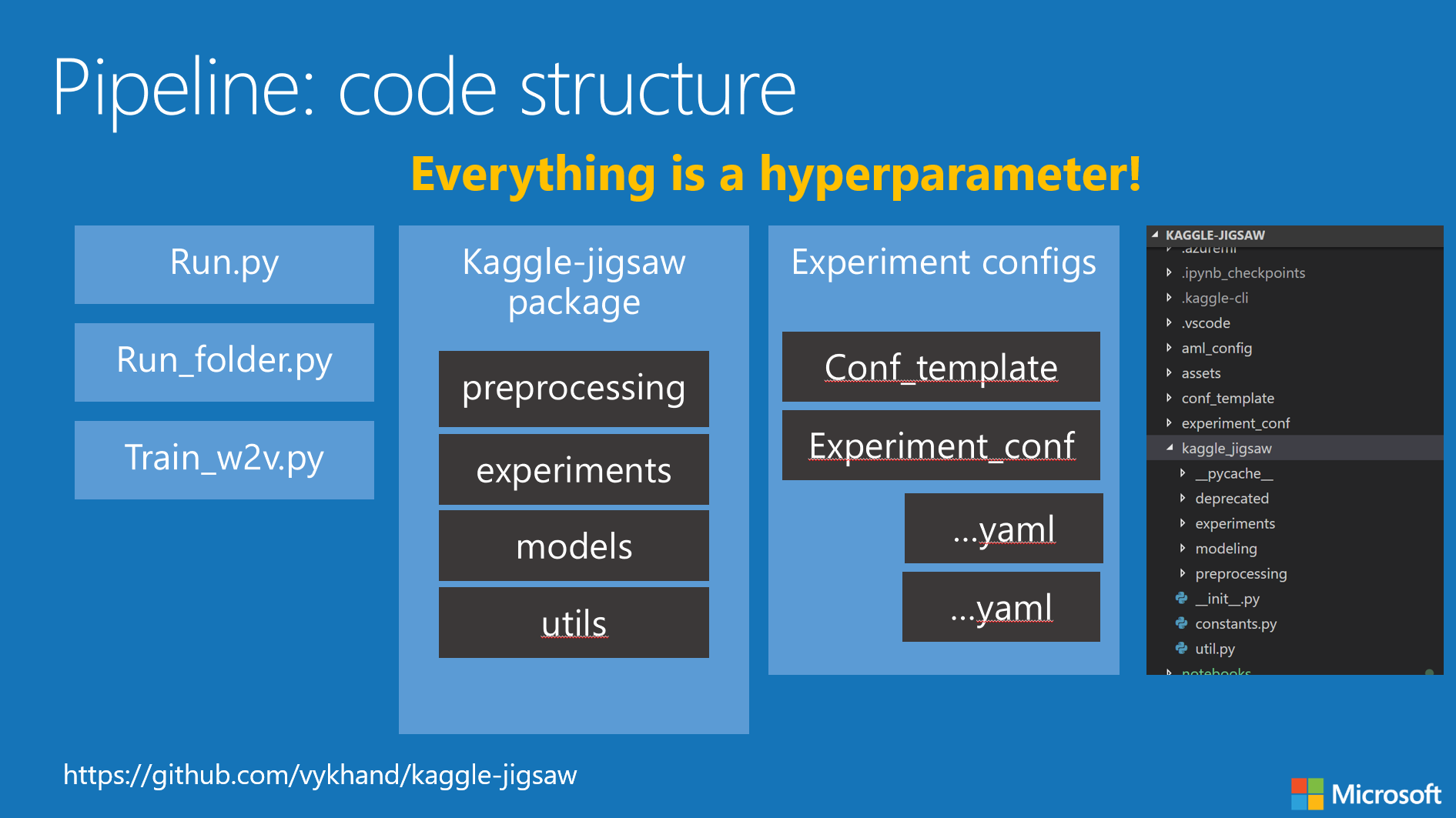
Pipeline intends to be extendable and configurable to support “everything is a hyperparameter” approach.
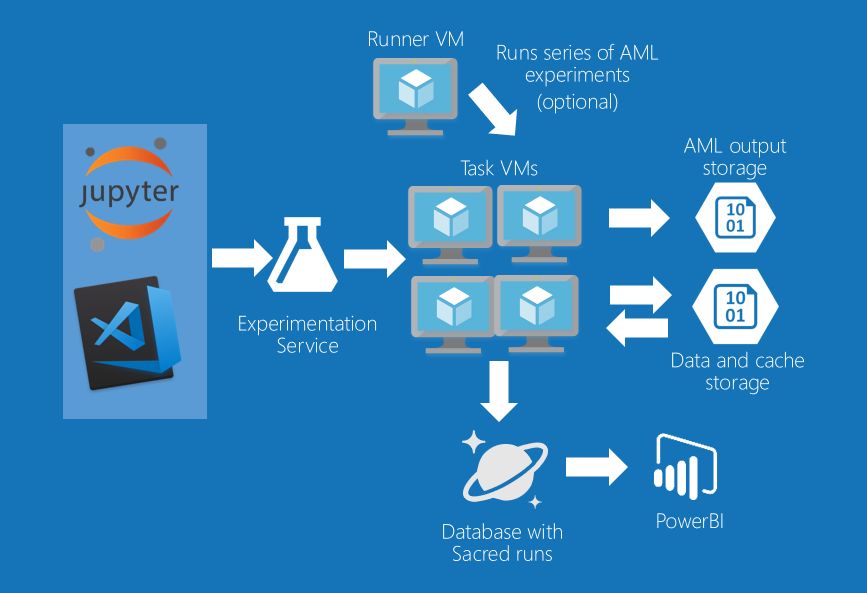
Architecture
Below is the diagram of compute architecture. I used cheap Windows DSVM (burst instances) to run series of experiments and stop the machines after all experiments are finished. I used 2-3 CPU VMs and 2 GPU vms to run experiments. I used minimial sized collections for CosmosDB to store “python/sacred” experiment information. Information from Azure ML runs is stored in a separate storage account, which has 1 folder per experiment, automatically populated by AML.
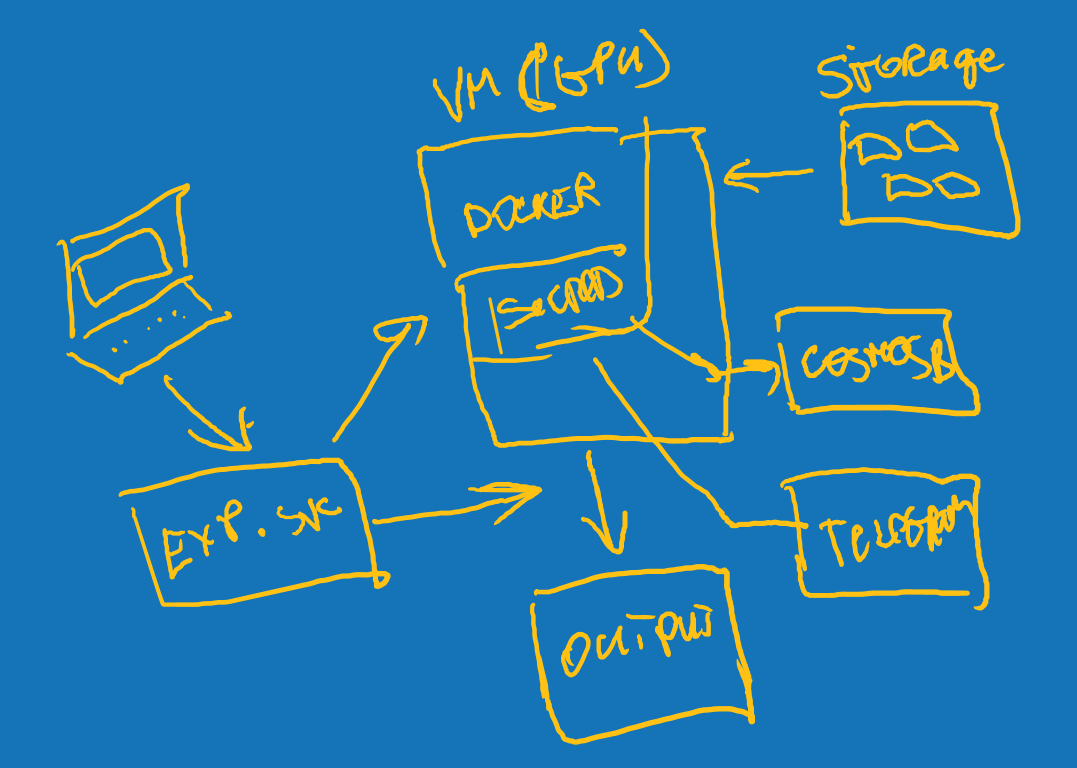
Experiment flow
- Run az ml command or use AML WB to start an experiment
- Azure ML Experimentation services send your code to VSTS/git special branch
- Azure ML Experimentation spins off a docker container on the appropriate compute and monitors the progress
- The pipeline code takes care of downloading all necessary files, so it can be ran on completely new VM
- Python Sacred library saves detailed telemetry to CosmosDB
- Python Sacred library notifies you via Telegram when experiment starts and ends, together with experiment results.
- When experiment ends, Azure ML saves all the resulting files to your Azure Storage account
TODO: draw better diagram
Deploying solution
This is not a turnkey solution. You will probably have to fix something or customize the code to your needs. Here is the approximate instruction how to set up the new deployment on your local machine from scratch.
- Run
git clone https://github.com/vykhand/kaggle-jigsawto clone the git repository - Install AML Workbench (AMLWB)
- Add github folder to AMLWB ()
- Log in to Azure using CLI
- Use the Example script to set up new VM
- Create Azure Storage and load data to it
- Create Cosmos DB for Sacred experiment monitoring.
- (Semi-optional) Create and configure Telegram bot.
- To be able to auto-shutdown VMs, get Azure subscription keys to be able to use Python management SDKs.
- Configure your runconfig environment variables, copying them from Example VM configuration to your
amlconfig\<vm>.runconfigfile and populate them with your own values. - If you are setting up a GPU VM, be sure to follow the instruction or copy the the Example GPU config
- You are now good to go. Refer to Standard Operating Procedures to understand how to run and configure experiments
Below you will find the details on (almost) each step
Setting up Azure ML Services
In this competition, I used experiment monitoring facility and notebook facility. Azure ML has many other capabilities as described at http://aka.ms/AzureMLGettingStarted
Getting the data and uploading it to storage account
Data for this competition is not distributed with this repository. You need to download it from the competition page located here. You can use Kaggle API to download data from command line.
There are also multiple other external files that I used for this competition:
To be able to run this solution, you need to set up your storage account, upload the required files there and configure the following variables in your .runconfig file:
"AZURE_STORAGE_ACCOUNT": ""
"AZURE_STORAGE_KEY": ""
"AZURE_CONTAINER_NAME": "kaggle-jigsaw"
Setting up Azure CLI and logging in
AZCLI should be set up together with Azure ML Workbench.
To make sure your PATH variable is set up to use the AML WB environment, you should either start cmd.exe or powershell from AMLWB, or open terminal with VS code in your project (if VS Code was set up by AMLWB)
Verify az verison:
az --version
You need to login with az by typing the command and following the instructions
az login
then you need to set your subscriptipon using the commands
# show subscriptions
az account list
# set subscription
az account set -s <subscription_name>
Setting up Azure Service principal
This is only needed to shutdown the VMs automatically. In order to set it up, you need to configure the following environment variables in your runconfig file:
"AZURE_CLIENT_ID": ""
"AZURE_CLIENT_SECRET": ""
"AZURE_TENANT_ID": ""
"AZURE_SUBSCRIPTION_ID":
This document describes how to find this information.
Setting up Cosmos DB
Create new cosmosDB instance with MongoDB API as default API. You don’t need anything else, as Sacred library will take care of creating your collections.
You need to specify your mongodb connection string using this env variable in your .runconfig file.
"COSMOS_URL": "mongodb://<>:<>"
this string can be found in the “Connection String” section of your CosmosDB in the Azure Portal.
Create and configure Telegram bot
This is non-essential but I don’t have a config option to switch it off. So if you don’t want to use it, you’ll have to comment all the lines like this:
**_experiment.observers.append(u.get_telegram_observer())
To configure telegram bot, please follow this instruction to set it up, and then update telegram.json file.
{
"token": "your telegram token",
"chat_id": "chat id"
}
Standard operating procedures
Running experiments from command line
Running GRU model with default config:
az ml experiment submit -c dsvm001 run.py GRU
Running with configuration file (modified file copied from conf_template)
az ml experiment submit -c dsvm001 run.py --conf experiment_conf/GRU.yaml
Running experiments with AMLWB
you can run run.py script with AML WB on your favourite compute, specifying configuration file or modeltype as an argument

Accessing experiment files
After you run the experiment, all the files are available in the output Azure Storage. You can easily access these files using Azure ML Workbench:
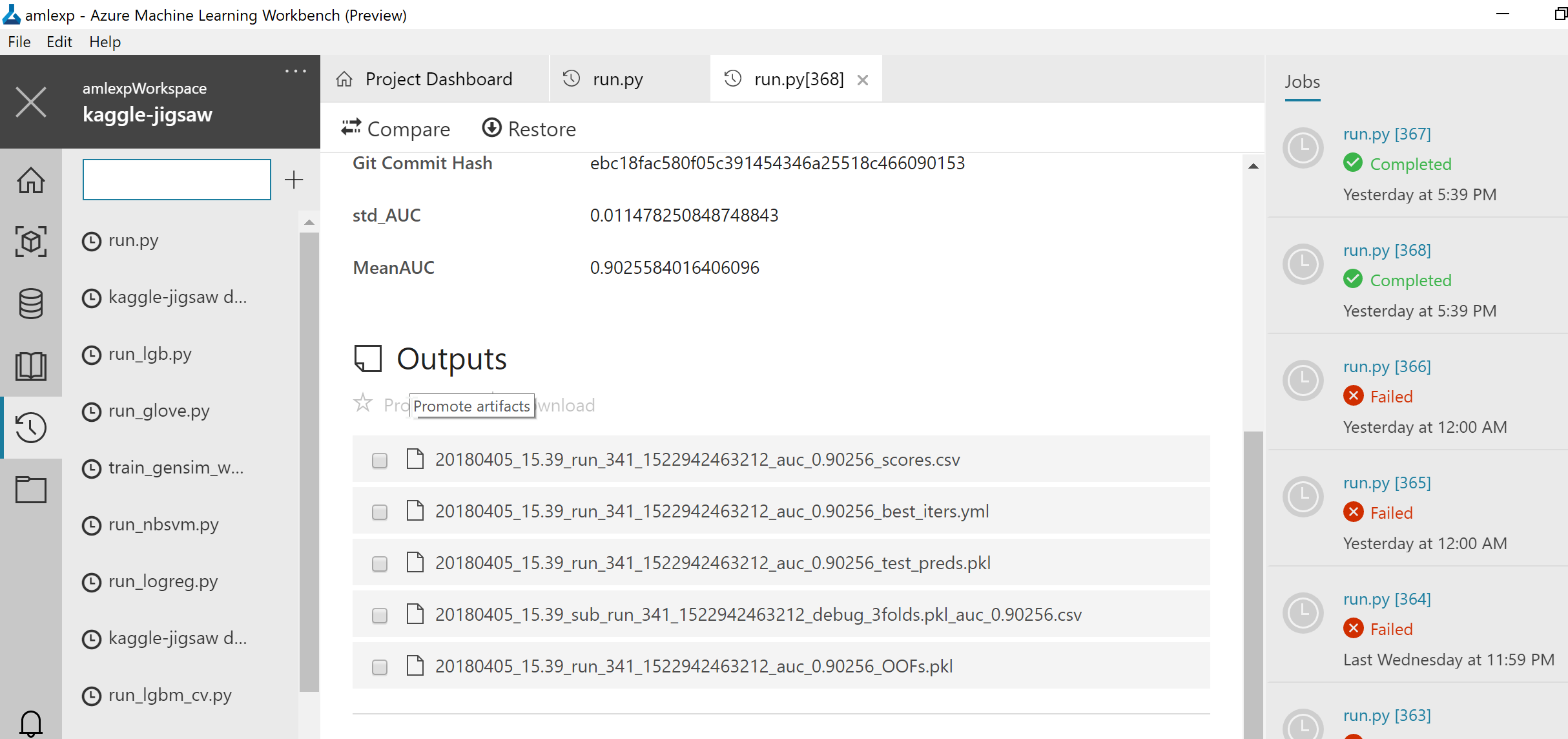
You can also locate your Azure Storage that is created together with your Azure ML Experimentation account and download files from there:
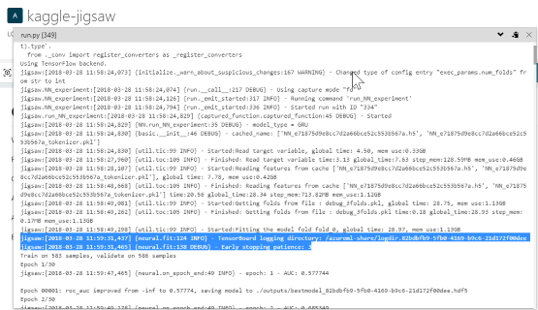
You just need the logdir name. Then log into your GPU VM and run:
tensorboard --logdir ~/.azureml/share/<your projectpath>/<logdir name>
Retrieving experiment results from CosmosDB
You can use the portal or VS Code plugin to access the data in CosmosDB:
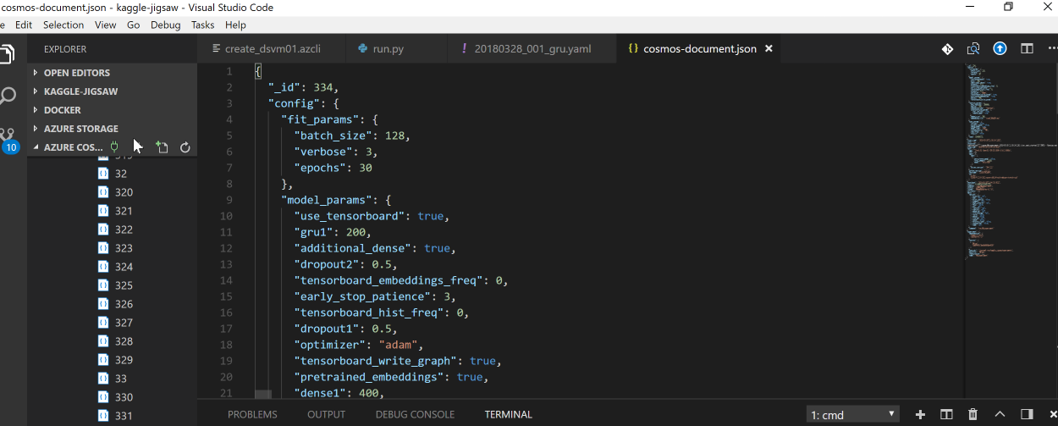
You can also set up the PowerBI dashboards that connect to your CosmosDB.
Modifying solution
Programmers love developing their own frameworks. There is a chance that you will hate mine. But in the case you’d like it, here are some pointers on modifying and extending it.
Project structure
| Folder name | Description |
|---|---|
aml_config |
Configuration files for compute |
conf_templates |
Experiment configuration templates for different models |
experiment_conf |
configurations of the individual experiments. No need to save every experiment here |
kaggle-jigsaw |
Main python package |
notebooks |
Jupyter notebooks with some musings |
scripts |
scripts to create compute |
root folder |
Run scripts and readme |
Python package structure
| Folder name | Description |
|---|---|
experiments |
Sacred experiments for a particular model type |
modeling |
Cross-validation logic, base classes for classifiers, and individual model classes |
preprocessing |
Base class for all preprocessors and data transofrmation classes |
constants.py |
This is where you can redefine default file names etc. |
util.py |
Auxilary routines for logging, dealing with Azure and other miscellaneous things |
Utilites util.py
responsible for
- Logging: time, memory
- Communicating with Azure Storage
- Get file from Azure storage “cache”
- Put file to cache
- check if file is available
- Shutting down the VMs
- Handling the cache for experiment preprocessed data
- calculates feature param md5 hash and downloads from Azure if file is available with this hash
Experiments
Code here simply chooses appropriate classes for model and preporcessors, and sets up Sacred.
Implemented the following models | file name | description | |—-|—-| | NN.py | all neural networks| | LGB.py | LightGBM| | sklearn | any sklearn-compatible model | | nbsvm | Naive Bayes with logistic regression |
Modeling
Implements base classes for models and specific classes. Also implements cross-validation logic.
Preprocessing
Implements base preprocessor class and specific classes for specific needs.
Run scripts
- Generic runner for all models
run.py - Run a folder of experiments on a VM and then shut it down
run_folder.py - Train embeddings on a vm
train_w2v.py